How Can Generative AI Impact Task Productivity?
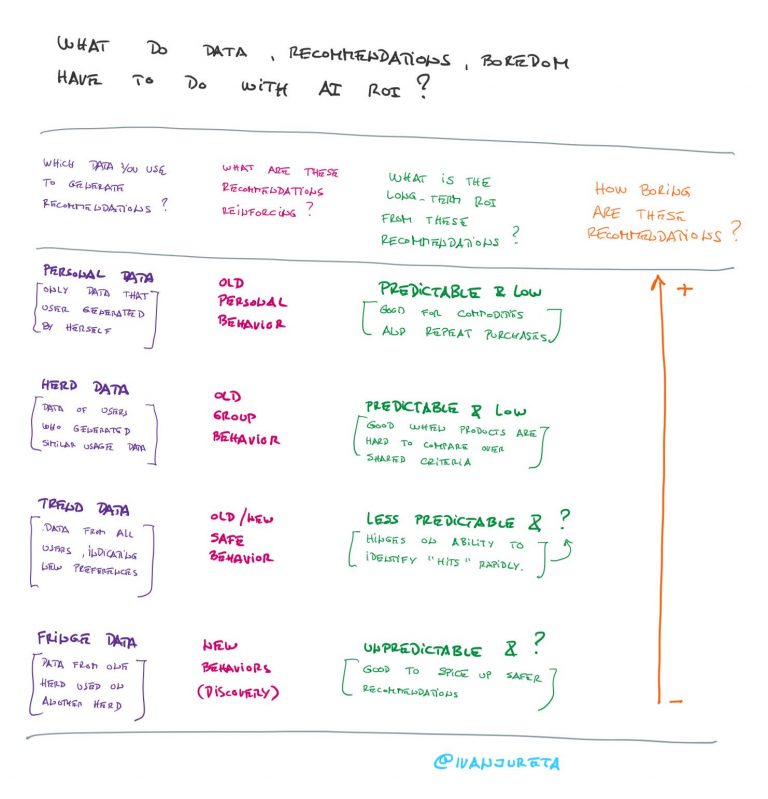
Generative AI shifts task productivity by altering how workers allocate time across subtasks and by reducing variance in initial work outputs.
Generative AI shifts task productivity by altering how workers allocate time across subtasks and by reducing variance in initial work outputs.
Generative AI reduces the marginal cost of producing drafts and ideas, which increases output per unit of time and especially benefits lower skilled workers.
We should reduce the cost of authorship and create an incentive mechanism that generates and assigns credibility to authors in a community.

Let’s start with the optimistic “yes”, and see if it remains acceptable. Before we get carried away, a few reminders. For an LLM to be a source of competitive advantage, it needs to be a resource that enables products or services of a firm “to perform at a higher level than others in the same…

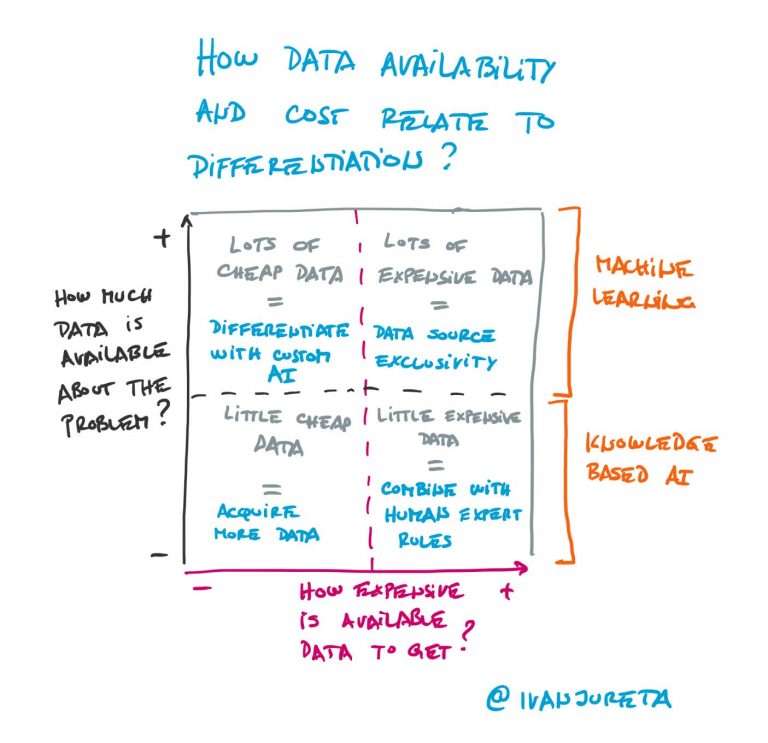
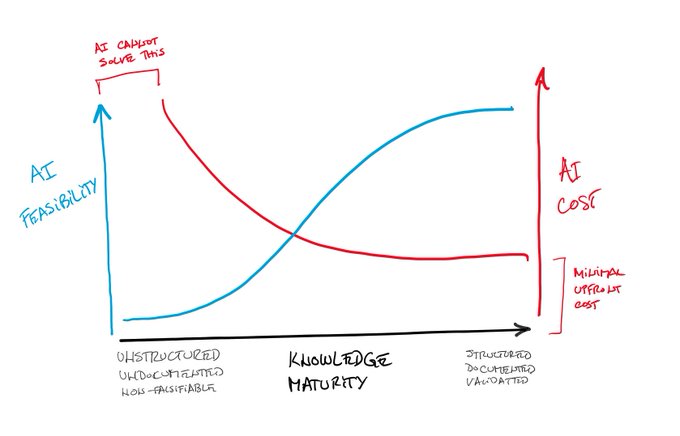
The less data there is, or the lower quality the data that is available, the more difficult it is to build AI based on statistical learning. For scarce data domains, the only way to design AI is to elicit knowledge from experts, design rules that represent that knowledge, parameterize them so that they apply to…

The short answer: careers that reward creative problem solving in domains with scarce knowledge. Let’s unpack that.
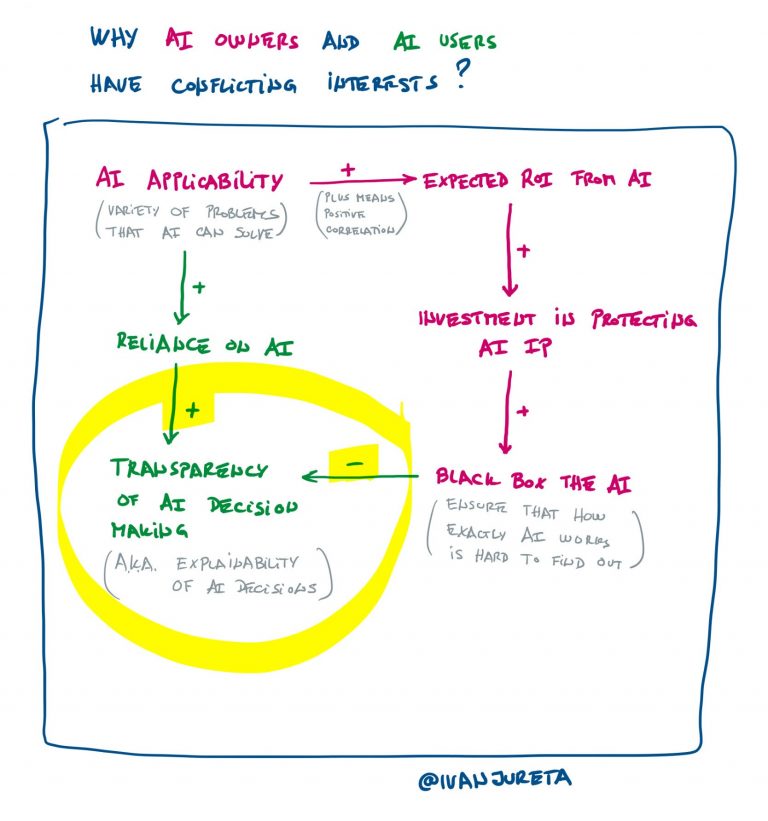
If AI is made for profit, then should its design be confidential? This choice is part of AI product strategy. The decision on this depends on the following at least. What is the relationship of each of these to AI confidentiality? Correctness: The more likely the AI / algorithm is to make errors, the more…

If there is a market for AI training datasets, then the price will be determined by supply and demand. How does the supplier set the price, and how does the buyer evaluate if the price is right? The question behind both of these is this: how to estimate the value of a training dataset? We…

In the creator economy, the creative individual sells content. The more attention the content captures, the more valuable it is. The incentive for the creator is status and payment for consumption of their content. Distribution channels are Internet platforms, where content is delivered as intended by the author, the platform does not transform it (other…

If any text can be training data for a Large Language Model, then any text is a training dataset that can be valued through a market for training data. Which datasets have high value? Wikipedia, StackOverflow, Reddit, Quora are examples that have value for different reasons, that is, because they can be used to train…
There is no high quality AI without high quality training data. A large language model (LLM) AI system, for example, may seem to deliver accurate and relevant information, but verifying that may be very hard – hence the effort into explainable AI, among others. If I wanted accurate and relevant legal advice, how much risk…