It requires paraconsistent reasoning and involves cognitive dissonance to think at the same time about requirements in the way promoted in mainstream requirements engineering, and then use the DevOps loop (and the broader model), a method that has been demonstrated to work (and I’ve seen it applied in a team I was part of in the past). Let’s look specifically at differences between the implied lifecycle of a requirement in each.
In mainstream requirements engineering [1,2,3,4], a requirement is defined as follows.
“The primary distinction necessary for requirements engineering is captured by two grammatical moods. Statements in the ‘indicative’ mood describe the environment as it is in the absence of the machine or regardless of the actions of the machine; these statements are often called ‘assumptions’ or ‘domain knowledge.’ Statements in the ‘optative’ mood describe the environment as we would like it to be and as we hope it will be when the machine is connected to the environment. Optative statements are commonly called ‘requirements.’ The ability to describe the environment in the optative mood makes it unnecessary to describe the machine.” [1]
The key idea above is that the requirement is defined on the basis of grammatical mood (which is related to speech acts, as John Mylopoulos, Stephane Faulkner, and I wrote some time ago [5]).
What is the lifecycle of a requirement? What is its state machine, if you prefer that language?
In the same paper [1], there is the statement of the requirements problem, as the problem one is solving when doing requirements engineering. The screenshot of the relevant fragment from paper [1] is shown below.

There are many important points to discuss about the above, and I’ve written about some elsewhere (e.g., [5], [6], [7]). The interesting one for the present text is that a requirement is either not satisfied (i.e., there is no proof for it from S, K) or is satisfied (there is a proof, that is, K, S entails R holds, and the requirement is in R).
That’s simple, only two states. However, there are some refinements of that across the literature. Namely:
- A requirement is elicited from stakeholders, although that isn’t a particularly interesting state; it can be equated, or is a specialization of “not satisfied”.
- A requirement can be validated or not validated, in reference to having stakeholders sign off on the documentation that captures the requirement; i.e., validation is about taking what was elicited, transforming it in some way, documenting it, and then going back to stakeholders so that they check that what they meant is accurately documented.
- A requirement can be verified or not, which corresponds to determining whether the requirement is entailed by the domain assumptions and the specification.
The interesting piece of DevOps here is the loop. Here it is, the picture comes from AWS “What is DevOps?” (here).
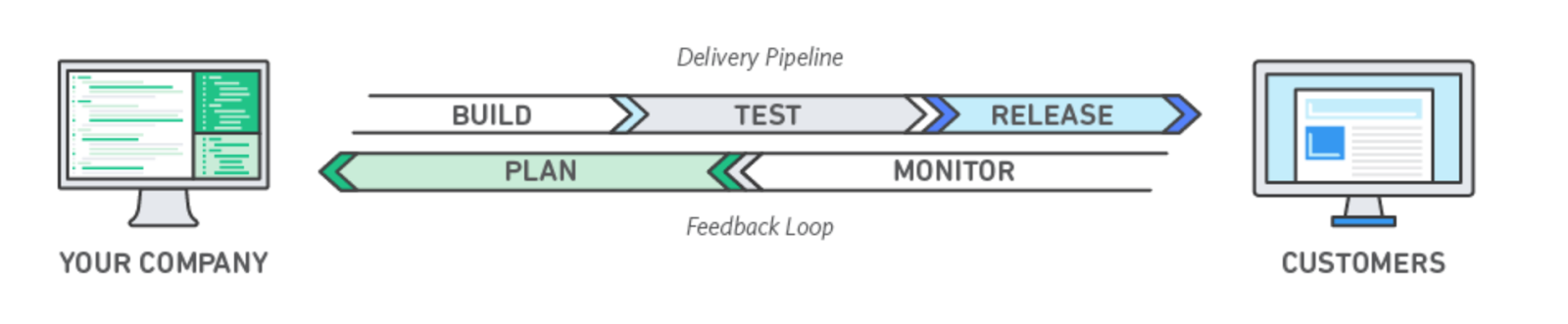
The distinction between “Your Company” on the left and “Customer” should be read in a broader way: “Your Company” can be a team in a company, and that team’s customers can be other teams, or individuals in the same company. On the left hand side are those satisfying requirements, and on the right those having requirements, or having expectations that should be satisfied (or better, depending on how well you want to satisfy them, as I wrote here and here).
In the DevOps loop, requirements are part of the Plan part of a cycle. Based on the monitoring, issues or opportunities are identified and they lead to requirements, which then shape what’s built, tested, released, and once in customers’ hands, monitored.
How is the lifecycle of a requirement in the DevOps loop different from the one in classical requirements engineering?
The fundamental difference is that the DevOps loop has a wider scope than design time, or the period during which the classical requirements problem is being solved. The loop suggests that there are five periods that matter:
- Plan, or plan time as I’ll refer to it below, is what’s usually referred to as design time, the time when requirements are engineered (which covers all steps from elicitation/discovery through validation), including solution design;
- Build time, the other name being development time, when the solution is implemented (note that the solution can obviously be an improvement of an existing one, so brownfield, not necessarily greenfield);
- Test time, when the implemented solution is tested, to verify if/how well it satisfies requirements;
- Release time, when the solution becomes available to customers;
- Monitoring time, when data is collected on and from customers about their experience with the implemented solution; this is often called runtime in the case of a software product / service.
The reason I was calling each step a time, i.e., plan time, build time, etc. is that I want to emphasize that each of these has a duration. This is obvious, but has non-obvious implications. One of the objectives when applying DevOps is to shorten those durations, but inevitably, they cannot be instantaneous.
The reason duration is important is that it cannot be ignored, and it cannot be ignored because while it is all happening, customer expectations can change, and we have to deal with requirements evolution / change / update (more on this here).
Therefore, when we write a requirement at Plan time, we are making assumptions about customer expectations at the end of the cycle of which that Plan step is part of. If I assume, on the basis of data collected at monitoring time that customers have a requirement X, I based that on data at time T1, but what I’m in fact doing is making assumptions about what customers require at time T2, which is the time when they will experience the solution that solves X.
This is where cognitive dissonance occurs: if you think the requirements problem is a problem that is located, so to speak, only in design time, or in DevOps only in plan time, then this goes against what is going on in the DevOps loop. Namely, any requirement considered, in a given DevOps cycle/iteration, at plan time, is an assumption about expectations at monitoring time, but at the same time, these requirements are based – at least in part – on data from the previous cycle’s monitoring time.
In short, although (K, S |- R) is interesting, it needs to be explicit about time. K, S, and R are defined at design/plan time, and we can demonstrate at design/plan time that entailment holds, that (K, S |- R) holds. Then, at monitoring time, we are verifying again that entailment holds, only now, it is no longer over design/plan time K and R, but over K’ and R’, which are, respectively, domain assumptions and requirements at monitoring time. As I wrote here, you can think that you satisfied requirements, but that does not guarantee you also satisfied customers.
References
- Zave, Pamela, and Michael Jackson. “Four dark corners of requirements engineering.” ACM transactions on Software Engineering and Methodology (TOSEM) 6.1 (1997): 1-30.
- Van Lamsweerde, Axel. “Goal-oriented requirements engineering: A guided tour.” Proceedings fifth ieee international symposium on requirements engineering. IEEE, 2001.
- Nuseibeh, Bashar, and Steve Easterbrook. “Requirements engineering: a roadmap.” Proceedings of the Conference on the Future of Software Engineering. 2000.
- Van Lamsweerde, Axel. “Requirements engineering in the year 00: A research perspective.” Proceedings of the 22nd international conference on Software engineering. 2000.
- Jureta, Ivan, John Mylopoulos, and Stephane Faulkner. “Revisiting the core ontology and problem in requirements engineering.” 2008 16th IEEE International Requirements Engineering Conference. IEEE, 2008.
- Jureta, Ivan J., et al. “Techne: Towards a new generation of requirements modeling languages with goals, preferences, and inconsistency handling.” 2010 18th IEEE International Requirements Engineering Conference. IEEE, 2010.
- Jureta, Ivan J., et al. “The requirements problem for adaptive systems.” ACM Transactions on Management Information Systems (TMIS) 5.3 (2014): 1-33.