How Can Generative AI Impact Task Productivity?
Generative AI shifts task productivity by altering how workers allocate time across subtasks and by reducing variance in initial work outputs.
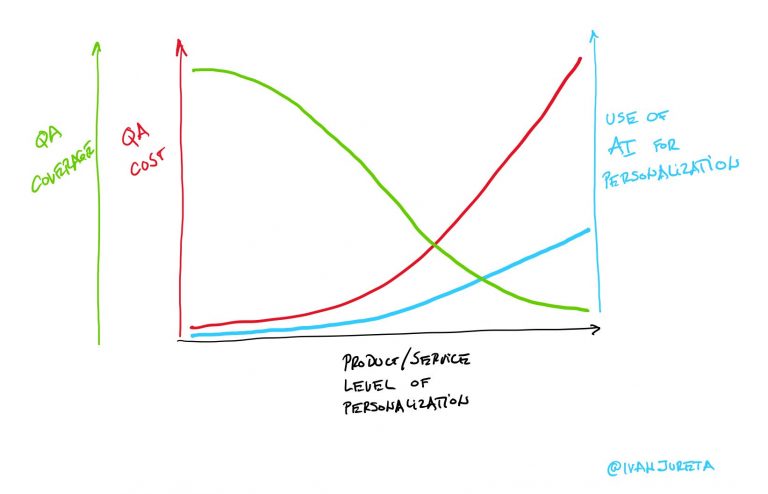
Generative AI shifts task productivity by altering how workers allocate time across subtasks and by reducing variance in initial work outputs.
Generative AI reduces the marginal cost of producing drafts and ideas, which increases output per unit of time and especially benefits lower skilled workers.
We should reduce the cost of authorship and create an incentive mechanism that generates and assigns credibility to authors in a community.

I wrote in another note (here) that AI cannot decide autonomously because it does not have self-made preferences. I argued that its preferences are always a reflection of those that its designers wanted it to exhibit, or that reflect patterns in training data. The irony with this argument is that if an AI is making…
In the context of human decision making, a decision is a commitment to a course of action (see the note here); it involves mental states that lead to specific actions. An AI system, as long as it is a combination of statistical learning algorithms and/or logic, and data, cannot have mental states in the same…

Let’s start with the optimistic “yes”, and see if it remains acceptable. Before we get carried away, a few reminders. For an LLM to be a source of competitive advantage, it needs to be a resource that enables products or services of a firm “to perform at a higher level than others in the same…

I use “depth of expertise” as a data quality dimension of AI training datasets. It describes how much a dataset reflects of expertise in a knowledge domain. This is not a common data quality dimension used in other contexts, and I haven’t seen it as such in discussions of, say, quality of data used for…

Just like l’art pour l’art, or art for the sake of art was the bohemian creed in the 19th century, it looks like there’s an “AI for the sake of AI” creed now when building general-purpose AI systems based on Large Language Models. Let’s say that the aim for a sustainable business are happy, paying,…

As currently drafted (2024), the Algorithmic Accountability Act does not require the algorithms and training data used in an AI System to be available for audit. (See my notes on the Act, starting with the one here.) The way that an auditor learns about the AI System is from documented impact assessments, which involve descriptions…

Artificial Intelligence, if incorrectly defined, is even more confusing than it can be. Sometimes, it is considered a technology, which itself is problematic: is it a technology on par with database management systems, for example, which are neutral with respect to the data they are implemented to manage in their specific instances? Or, is it…

The less data there is, or the lower quality the data that is available, the more difficult it is to build AI based on statistical learning. For scarce data domains, the only way to design AI is to elicit knowledge from experts, design rules that represent that knowledge, parameterize them so that they apply to…

The short answer: careers that reward creative problem solving in domains with scarce knowledge. Let’s unpack that.
If AI is made for profit, then should its design be confidential? This choice is part of AI product strategy. The decision on this depends on the following at least. What is the relationship of each of these to AI confidentiality? Correctness: The more likely the AI / algorithm is to make errors, the more…

The short answer is “No”, and the reasons for it are interesting. An AI system is opaque if it is impossible or costly for it (or people auditing it) to explain why it gave some specific outputs. Opacity is undesirable in general – see my note here. So this question applies for both those outputs…

Opacity, complexity, bias, and unpredictability are key negative nonfunctional requirements to address when designing AI systems. Negative means that if you have a design that reduces opacity, for example, relative to another design, the former is preferred, all else being equal. The first thing is to understand what each term refers to in general, that…
How good of an explanation can be provided by Artificial Intelligence built using statistical learning methods? This note is slightly more complicated than my usual ones. In logic, conclusions are computed from premises by applying well defined rules. When a conclusion is the appropriate one, given the premises and the rules, then it is said…

If there is a market for AI training datasets, then the price will be determined by supply and demand. How does the supplier set the price, and how does the buyer evaluate if the price is right? The question behind both of these is this: how to estimate the value of a training dataset? We…

In the creator economy, the creative individual sells content. The more attention the content captures, the more valuable it is. The incentive for the creator is status and payment for consumption of their content. Distribution channels are Internet platforms, where content is delivered as intended by the author, the platform does not transform it (other…

If any text can be training data for a Large Language Model, then any text is a training dataset that can be valued through a market for training data. Which datasets have high value? Wikipedia, StackOverflow, Reddit, Quora are examples that have value for different reasons, that is, because they can be used to train…
There is no high quality AI without high quality training data. A large language model (LLM) AI system, for example, may seem to deliver accurate and relevant information, but verifying that may be very hard – hence the effort into explainable AI, among others. If I wanted accurate and relevant legal advice, how much risk…

There are, roughly speaking, three problems to solve for an Artificial Intelligence system to comply with AI regulations in China (see the note here) and likely future regulation in the USA (see the notes on the Algorithmic Accountability Act, starting here): Using available, large-scale crawled web/Internet data is a low-cost (it’s all relative) approach to…
If an artificial intelligence system is trained on large-scale crawled web/Internet data, can it comply with the Algorithmic Accountability Act? For the sake of discussion, I assume below that (1) the Act is passed, which it is not at the time of writing, and (2) the Act applies to the system (for more on applicability,…

Sections 6 through 11 of the Algorithmic Accountability Act (2022 and 2023) have less practical implications for product management. They ensure that the Act, if passed, becomes part of the Federal Trade Commission Act, as well as introduce requirements that the FTC needs to meet when implementing the Act. This text follows my notes on…

To say that something is able to decide requires that it is able to conceive more than the single course of action in a situation where it is triggered to act, that it can compare these alternative courses of action prior to choosing one, and that it likes one over all others as a result…

Section 5 specifies the content of the summary report to be submitted about an automated decision system. This text follows my notes on Sections 1 and 2, Section 3 and Section 4 of the Algorithmic Accountability Act (2022 and 2023). This is the fourth of a series of texts where I’m providing a critical reading…
Section 4 provides requirements that influence how to do the impact assessment of an automated decision system on consumers/users. This text follows my notes on Sections 1 and 2, and Section 3 of the Algorithmic Accountability Act (2022 and 2023). When (if?) the Act becomes law, it will apply across all kinds of software products,…
This text follows my notes on Sections 1 and 2 of the the Algorithmic Accountability Act (2022 and 2023). When (if?) the Act becomes law, it will apply across all kinds of software products, or more generally, products and services which rely in any way on algorithms to support decision making. This makes it necessary…

The Algorithmic Accountability Act (2022 and 2023) applies to many more settings than what is in early 2024 considered as Artificial Intelligence. It applies across all kinds of software products, or more generally, products and services which rely in any way on algorithms to support decision making. This makes it necessary for any product manager…

The Algorithmic Accountability Act of 2022, here, applies to systems that help make, or themselves make (or recommend) “critical decisions”. Determining if something is a “critical decision” determines if a system is subject to the Act or not. Hence the interest in the discussion, below, of the definition of “critical decision”. The Act defines a…

The Algorithmic Accountability Act of 2022, here, is a very interesting text if you need to design or govern a process for the design of software that involves some form of AI. The Act has no concept of AI, but of Automated Decision System, defined as follows. Section 2 (2): “The term “automated decision system”…

Does the EU AI Act apply to most, if not all software? It is probably not what was intended, but it may well be the case. The EU AI Act, here, applies to “artificial intelligence systems” (AI system), and defines AI systems as follows: ‘artificial intelligence system’ (AI system) means software that is developed with…

In April 2023, the Cyberspace Administration of China released a draft Regulation for Generative Artificial Intelligence Services. The note below continues the previous one related to the same regulation, here. One of the requirements on Generative AI is that the authenticity, accuracy, objectivity, and diversity of the data can be guaranteed. My intent below is…

In a previous note, here, I wrote that one of the requirements for Generative AI products/services in China is that if it uses data that contains personal information, the consent of the holder of the personal information needs to be obtained. It seems self-evident that this needs to be a requirement. It is also not…
IP compliance requirements on generative AI reduce the readily and cheaply available amount of training data, with a few consequences on how product development and product operations are done.

If an AI is not predictable by design, then the purpose of governing it is to ensure that it gives the right answers (actions) most of the time, and that when it fails, the consequences are negligible, or that it can only fail on inconsequential questions, goals, or tasks.

Can “an artificial intelligence machine be an ‘inventor’ under the Patent Act”? According to the Memorandum Opinion filed on September 2, 2021, in the case 1:20-cv-00903, the US Patent and Trademark Office (USPTO) requires that the inventor is one or more people [1]. An “AI machine” cannot be named an inventor on a patent that…